LoadingĐang tải nội dung...Vui lòng chờ trong giây lát.Đang tải nội dung...
LoadingĐang tải bài viết...Vui lòng chờ trong giây lát.Đang tải bài viết...
LoadingĐang tải bài viết...Vui lòng chờ trong giây lát.Đang tải bài viết...
Once caching is introduced into a production system, a new question arises:
If data is already stored in the cache, how should applications read and write that data?
At first glance, the answer seems straightforward. However, this is where various caching strategies begin to emerge.
Each strategy attempts to balance three key factors:
Performance
Data Consistency
Implementation Complexity
There is no single strategy that fits every system. Understanding how each approach works is essential for choosing the right one for your specific use case.
Characteristics
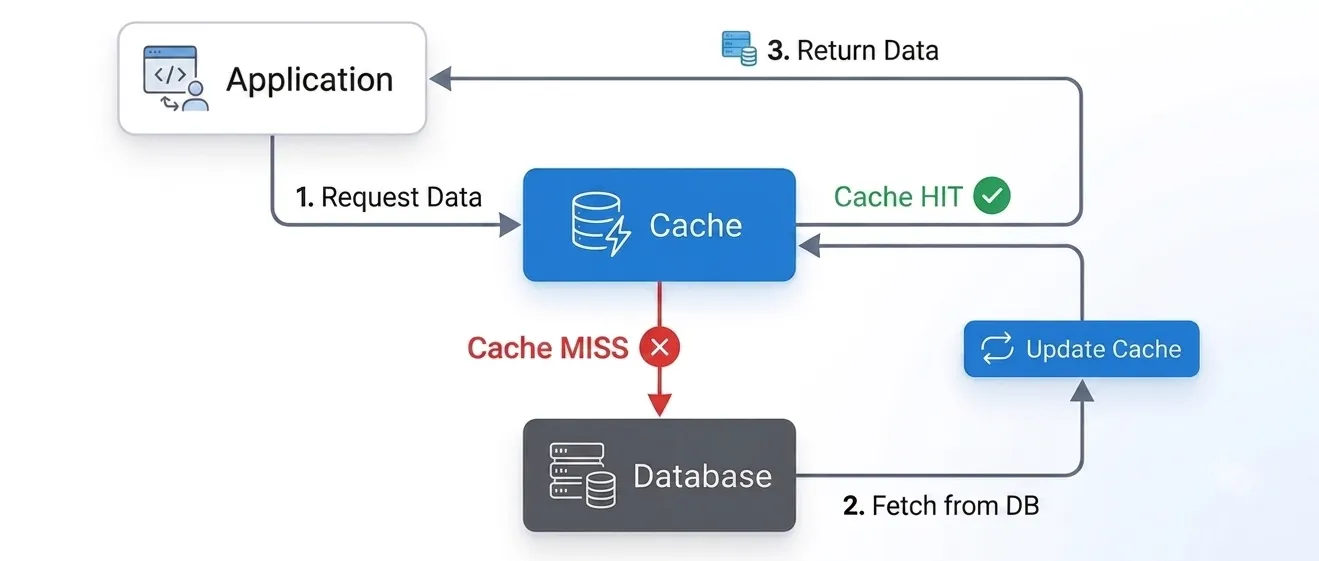
The application is responsible for managing all interactions between the Cache and the Database.
This is the most common caching model used today because it is simple and easy to implement.
These two strategies are commonly used together.
When a cache hit occurs:
Return the data directly from the cache.
When a cache miss occurs:
Read data from the Database.
Store the data in the Cache.
Return the result to the user.
When should cached data be refreshed?
Common scenarios include:
The underlying data has been modified.
The cached data has been deleted or expired.
When either condition occurs:
The cache is not updated immediately.
Data is only loaded back into the cache when a subsequent read request occurs.
A user updates their profile:
Update the customer profile in the database.
Remove the cache entry associated with the updated profile.
The next profile request results in a cache miss.
The application queries the database and repopulates the cache.
Simple and easy to implement throughout an application.
Only caches data that is actually being used.
Reduces cache memory consumption because only frequently accessed data is stored.
The first request after a cache miss always hits the database.
Initial reads after cache expiration may experience higher latency.
Susceptible to Cache Stampede, where multiple requests simultaneously encounter a cache miss and overload the database.
Cache logic can become difficult to manage when scattered across the codebase.
Product Catalogs
User Profiles
CMS Platforms
Most CRUD-Based Systems
Data that is frequently updated but not always read
Characteristics
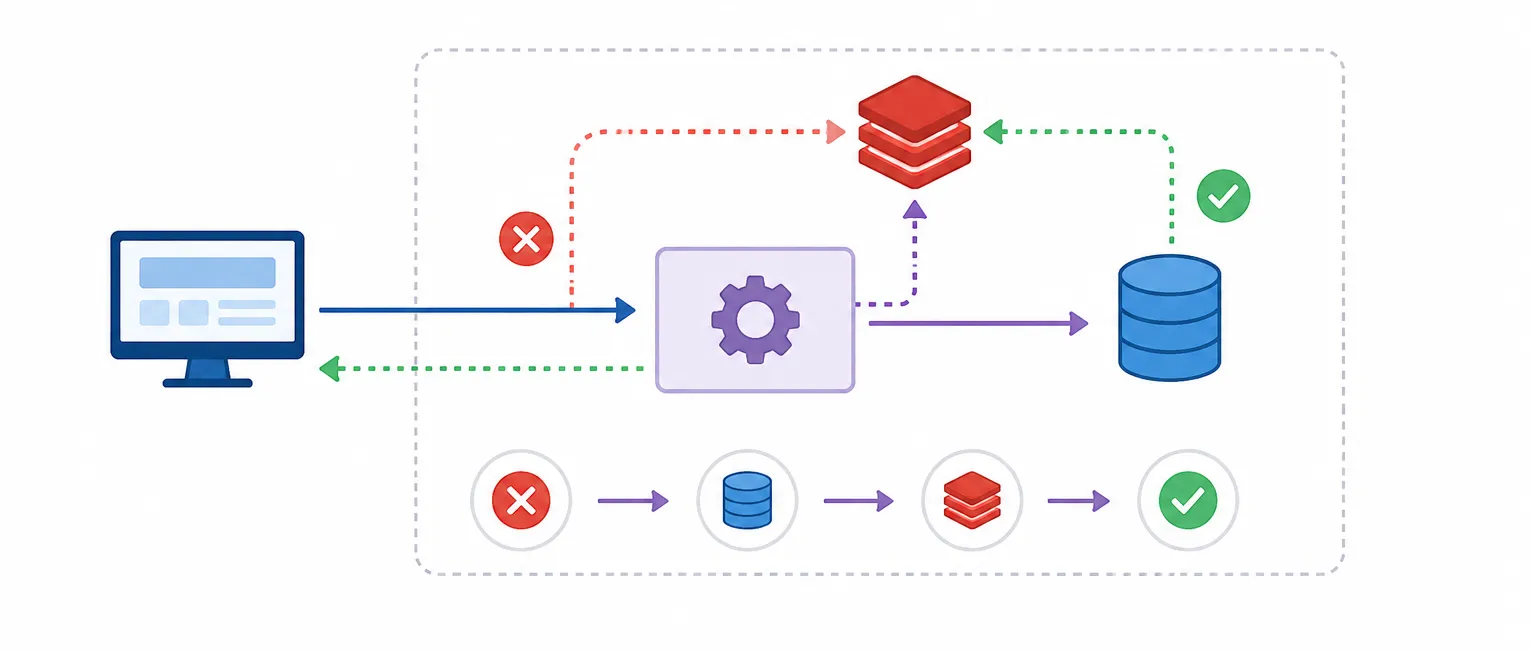
A Cache Loader or Data Source Adapter is configured within the cache layer.
The cache layer takes full responsibility for handling reads and writes.
This approach is commonly found in large-scale systems or platforms where multiple services share the same data.
When a cache miss occurs:
The Cache Layer automatically retrieves data from the database.
The cache is updated automatically.
The result is returned to the application.
The application does not need to know where the data originates.
When data is written:
Application
|
v
Cache Layer
|
+--> Cache
|
+--> Database
After the write operation:
Cache = New Value
DB = New Value
An application updates a product price:
Update Product Price
|
v
Cache Layer
|
+----+----+
| |
Cache Database
Result:
Cache = $100
DB = $100
Subsequent reads:
Read Product Price
|
v
Cache Hit
Caching logic is centralized in a single layer.
Applications become simpler.
Cache and Database are updated within the same write flow, providing strong consistency.
Reads immediately after writes are typically cache hits.
Easier to manage when multiple services access the same data.
Requires a Cache Provider or Cache Loader.
More complex to implement.
Every write operation updates both Cache and Database, increasing write latency and I/O operations.
Large-Scale Systems
Microservices Architectures
Pricing Services
Product Information Services
Metadata Services
Shared Data Access Across Multiple Services
The strategies discussed above primarily focus on maintaining data consistency.
Some systems are willing to trade consistency for faster write performance.
Data is written to the Cache first and persisted to the Database asynchronously at a later time.
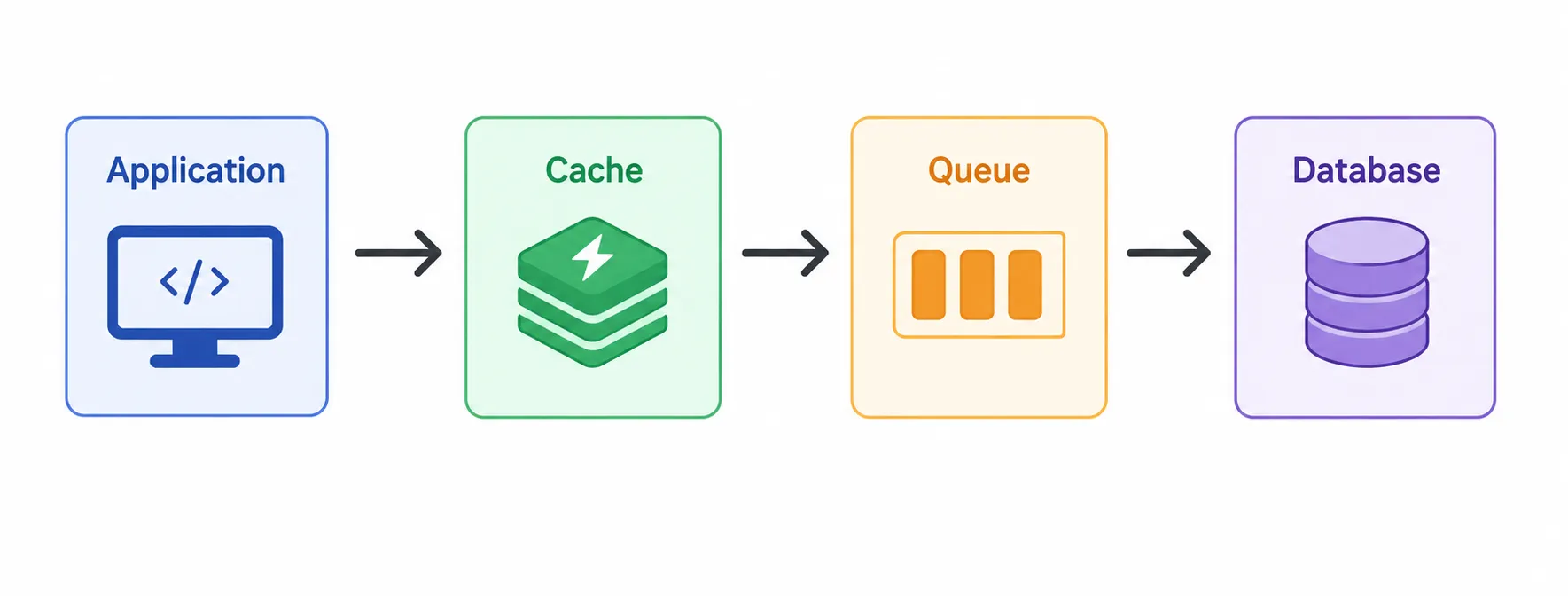
Extremely fast write performance.
Reduces database load.
Efficient support for batch writes.
Eventual Consistency.
Risk of data loss if failures occur before data is persisted.
Rollback and recovery become more complex.
Like Counters
View Counters
Analytics Systems
Logging
Telemetry Data
Payment Systems
Account Balances
Financial Transactions
Real-Time Inventory Management
This strategy is typically used only for high-value or frequently accessed data.
Consider the following example:
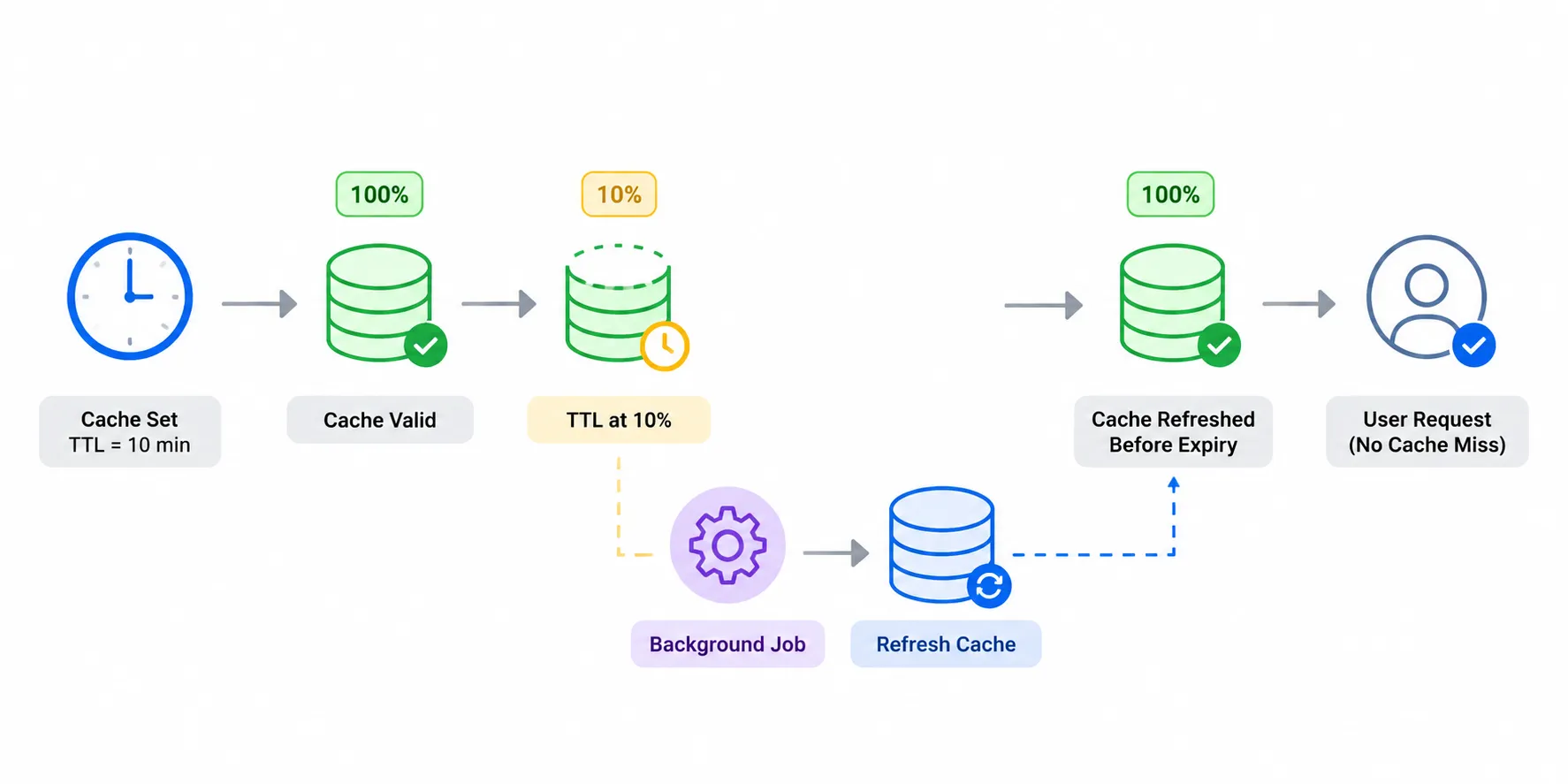
TTL = 10 minutes
10:00 Cache Expired
10:01 User Request
10:01 Database Query
The first user request after expiration must wait for a database query.
Refresh Ahead proactively updates cache entries before they expire.
TTL Remaining = 10%
|
v
Background Job
|
v
Refresh Cache
Cache remains warm.
Fewer cache misses.
More stable and predictable latency.
Homepages
Trending Products
Dashboards
Configuration Data
Frequently Accessed Data